Source :-
Category: Apache
Apache Kafka – Producer (Java Code)
Apache Kafka – Use cases
Here is a description of a few of the popular use cases for Apache Kafka™. For an overview of a number of these areas in action, see this blog post.
Messaging
Kafka works well as a replacement for a more traditional message broker. Message brokers are used for a variety of reasons (to decouple processing from data producers, to buffer unprocessed messages, etc). In comparison to most messaging systems Kafka has better throughput, built-in partitioning, replication, and fault-tolerance which makes it a good solution for large scale message processing applications.
In our experience messaging uses are often comparatively low-throughput, but may require low end-to-end latency and often depend on the strong durability guarantees Kafka provides.
In this domain Kafka is comparable to traditional messaging systems such as ActiveMQ or RabbitMQ.
Website Activity Tracking
The original use case for Kafka was to be able to rebuild a user activity tracking pipeline as a set of real-time publish-subscribe feeds. This means site activity (page views, searches, or other actions users may take) is published to central topics with one topic per activity type. These feeds are available for subscription for a range of use cases including real-time processing, real-time monitoring, and loading into Hadoop or offline data warehousing systems for offline processing and reporting.
Activity tracking is often very high volume as many activity messages are generated for each user page view.
Metrics
Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.
Log Aggregation
Many people use Kafka as a replacement for a log aggregation solution. Log aggregation typically collects physical log files off servers and puts them in a central place (a file server or HDFS perhaps) for processing. Kafka abstracts away the details of files and gives a cleaner abstraction of log or event data as a stream of messages. This allows for lower-latency processing and easier support for multiple data sources and distributed data consumption. In comparison to log-centric systems like Scribe or Flume, Kafka offers equally good performance, stronger durability guarantees due to replication, and much lower end-to-end latency.
Stream Processing
Many users of Kafka process data in processing pipelines consisting of multiple stages, where raw input data is consumed from Kafka topics and then aggregated, enriched, or otherwise transformed into new topics for further consumption or follow-up processing. For example, a processing pipeline for recommending news articles might crawl article content from RSS feeds and publish it to an “articles” topic; further processing might normalize or deduplicate this content and published the cleansed article content to a new topic; a final processing stage might attempt to recommend this content to users. Such processing pipelines create graphs of real-time data flows based on the individual topics. Starting in 0.10.0.0, a light-weight but powerful stream processing library called Kafka Streams is available in Apache Kafka to perform such data processing as described above. Apart from Kafka Streams, alternative open source stream processing tools include Apache Storm and Apache Samza.
Event Sourcing
Event sourcing is a style of application design where state changes are logged as a time-ordered sequence of records. Kafka’s support for very large stored log data makes it an excellent backend for an application built in this style.
Commit Log
Kafka can serve as a kind of external commit-log for a distributed system. The log helps replicate data between nodes and acts as a re-syncing mechanism for failed nodes to restore their data. The log compaction feature in Kafka helps support this usage. In this usage Kafka is similar to Apache BookKeeperproject.
Apache Kafka – Producer / Consumer Basic Test (With Youtube Video)
In Kafka Server Make the following changes in configuration.property
-
cd $KAFKA_HOME/config
-
vim configuration.property
Config File Changes :-
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an “AS IS” BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see kafka.server.KafkaConfig for additional details and defaults############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0############################# Socket Server Settings #############################
listeners=PLAINTEXT://:9092
listeners=PLAINTEXT://<Kafka-Server-IP>:9092
# The port the socket server listens on
#port=9092# Hostname the broker will bind to. If not set, the server will bind to all interfaces
#host.name=localhost# Hostname the broker will advertise to producers and consumers. If not set, it uses the
# value for “host.name” if configured. Otherwise, it will use the value returned from
# java.net.InetAddress.getCanonicalHostName().
#advertised.host.name=<hostname routable by clients>
advertised.host.name=<kafka-server-ip># The port to publish to ZooKeeper for clients to use. If this is not set,
# it will publish the same port that the broker binds to.
#advertised.port=<port accessible by clients>
advertised.port=9092# The number of threads handling network requests
2. Considering there is a Kafka Server and 2 different Servers in which the Client for Kafka is Installed
At Producer Client Server :-
-
cd $KAFKA_HOME
-
./kafka-console-producer.sh –broker-list <kafka-server-ip>:<kafka-port> –topic <topic-name>
At Consumer Client Server :-
-
cd $KAFKA_HOME
-
./kafka-console-consumer.sh –zookeeper <kafka-server-ip>:2181 –topic <topic-name> –from-beginning
PRODUCER END

CONSUMER END

Apache Kafka – Fundamentals & Workflow
Before moving deep into the Kafka, you must aware of the main terminologies such as topics, brokers, producers and consumers. The following diagram illustrates the main terminologies and the table describes the diagram components in detail.
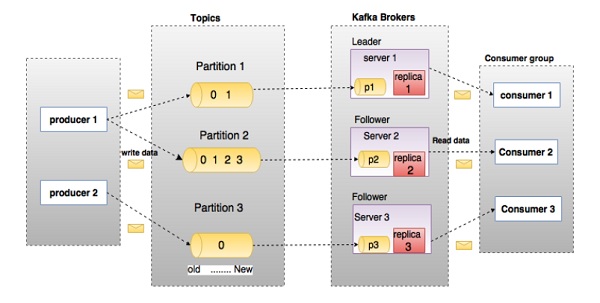
In the above diagram, a topic is configured into three partitions. Partition 1 has two offset factors 0 and 1. Partition 2 has four offset factors 0, 1, 2, and 3. Partition 3 has one offset factor 0. The id of the replica is same as the id of the server that hosts it.
Assume, if the replication factor of the topic is set to 3, then Kafka will create 3 identical replicas of each partition and place them in the cluster to make available for all its operations. To balance a load in cluster, each broker stores one or more of those partitions. Multiple producers and consumers can publish and retrieve messages at the same time.
| S.No | Components and Description |
|---|---|
| 1 | Topics
A stream of messages belonging to a particular category is called a topic. Data is stored in topics. Topics are split into partitions. For each topic, Kafka keeps a mini-mum of one partition. Each such partition contains messages in an immutable ordered sequence. A partition is implemented as a set of segment files of equal sizes. |
| 2 | Partition
Topics may have many partitions, so it can handle an arbitrary amount of data. |
| 3 | Partition offset
Each partitioned message has a unique sequence id called as |
| 4 | Replicas of partition
Replicas are nothing but |
| 5 | Brokers
|
| 6 | Kafka Cluster
Kafka’s having more than one broker are called as Kafka cluster. A Kafka cluster can be expanded without downtime. These clusters are used to manage the persistence and replication of message data. |
| 7 | Producers
Producers are the publisher of messages to one or more Kafka topics. Producers send data to Kafka brokers. Every time a producer pub-lishes a message to a broker, the broker simply appends the message to the last segment file. Actually, the message will be appended to a partition. Producer can also send messages to a partition of their choice. |
| 8 | Consumers
Consumers read data from brokers. Consumers subscribes to one or more topics and consume published messages by pulling data from the brokers. |
| 9 | Leader
|
| 10 | Follower
Node which follows leader instructions are called as follower. If the leader fails, one of the follower will automatically become the new leader. A follower acts as normal consumer, pulls messages and up-dates its own data store. |
As of now, we discussed the core concepts of Kafka. Let us now throw some light on the workflow of Kafka.
Kafka is simply a collection of topics split into one or more partitions. A Kafka partition is a linearly ordered sequence of messages, where each message is identified by their index (called as offset). All the data in a Kafka cluster is the disjointed union of partitions. Incoming messages are written at the end of a partition and messages are sequentially read by consumers. Durability is provided by replicating messages to different brokers.
Kafka provides both pub-sub and queue based messaging system in a fast, reliable, persisted, fault-tolerance and zero downtime manner. In both cases, producers simply send the message to a topic and consumer can choose any one type of messaging system depending on their need. Let us follow the steps in the next section to understand how the consumer can choose the messaging system of their choice.
Workflow of Pub-Sub Messaging
Following is the step wise workflow of the Pub-Sub Messaging −
- Producers send message to a topic at regular intervals.
- Kafka broker stores all messages in the partitions configured for that particular topic. It ensures the messages are equally shared between partitions. If the producer sends two messages and there are two partitions, Kafka will store one message in the first partition and the second message in the second partition.
- Consumer subscribes to a specific topic.
- Once the consumer subscribes to a topic, Kafka will provide the current offset of the topic to the consumer and also saves the offset in the Zookeeper ensemble.
- Consumer will request the Kafka in a regular interval (like 100 Ms) for new messages.
- Once Kafka receives the messages from producers, it forwards these messages to the consumers.
- Consumer will receive the message and process it.
- Once the messages are processed, consumer will send an acknowledgement to the Kafka broker.
- Once Kafka receives an acknowledgement, it changes the offset to the new value and updates it in the Zookeeper. Since offsets are maintained in the Zookeeper, the consumer can read next message correctly even during server outrages.
- This above flow will repeat until the consumer stops the request.
- Consumer has the option to rewind/skip to the desired offset of a topic at any time and read all the subsequent messages.
Workflow of Queue Messaging / Consumer Group
In a queue messaging system instead of a single consumer, a group of consumers having the same Group ID
will subscribe to a topic. In simple terms, consumers subscribing to a topic with same Group ID
are considered as a single group and the messages are shared among them. Let us check the actual workflow of this system.
- Producers send message to a topic in a regular interval.
- Kafka stores all messages in the partitions configured for that particular topic similar to the earlier scenario.
- A single consumer subscribes to a specific topic, assume
Topic-01
withGroup ID
asGroup-1
. - Kafka interacts with the consumer in the same way as Pub-Sub Messaging until new consumer subscribes the same topic,
Topic-01
with the sameGroup ID
asGroup-1
. - Once the new consumer arrives, Kafka switches its operation to share mode and shares the data between the two consumers. This sharing will go on until the number of con-sumers reach the number of partition configured for that particular topic.
- Once the number of consumer exceeds the number of partitions, the new consumer will not receive any further message until any one of the existing consumer unsubscribes. This scenario arises because each consumer in Kafka will be assigned a minimum of one partition and once all the partitions are assigned to the existing consumers, the new consumers will have to wait.
- This feature is also called as
Consumer Group
. In the same way, Kafka will provide the best of both the systems in a very simple and efficient manner.
Role of ZooKeeper
A critical dependency of Apache Kafka is Apache Zookeeper, which is a distributed configuration and synchronization service. Zookeeper serves as the coordination interface between the Kafka brokers and consumers. The Kafka servers share information via a Zookeeper cluster. Kafka stores basic metadata in Zookeeper such as information about topics, brokers, consumer offsets (queue readers) and so on.
Since all the critical information is stored in the Zookeeper and it normally replicates this data across its ensemble, failure of Kafka broker / Zookeeper does not affect the state of the Kafka cluster. Kafka will restore the state, once the Zookeeper restarts. This gives zero downtime for Kafka. The leader election between the Kafka broker is also done by using Zookeeper in the event of leader failure.

You must be logged in to post a comment.